
Research Projects
Here you can find some more background information on all of the projects I have worked on. All of these projects I have referenced are not associated with any coursework or class projects from any University. For more references and a better look at some of the smaller projects I worked on, visit my Repositories page on GitHub.
To collaborate on any of these projects feel free to contact me!
-
Topaz Labs: ML Models for Image & Video Enhancement
At Topaz Labs, I work on designing, training, and integrating ML models for various aspects of image and video processing:
- Quality Assessment Models: Developed models to evaluate image and video quality metrics
- Segmentation Models: Created advanced segmentation models for precise object and region detection
- Semantic Understanding: Implemented models for understanding image content and context
- Enhancement Pipeline: Architected a zero-click image and video enhancement pipeline for API users
Key achievements include:
- Deployed internal tools for scalable data analysis and model comparison
- Implemented user data tracking and trained suggestion systems
- Developed autopilot tools for automated image enhancement
-
Joby AI: Intelligent Job Matching Platform
As a cofounder at Joby AI, I led the development of an intelligent job matching platform that leverages advanced AI technologies:
- Vector Search Models: Implemented and fine-tuned contrastive learning models for improved job matching accuracy
- LLM Agents: Developed sophisticated agents for automated job scraping from career pages and job boards
- Automation Tools: Created tools for automated job applications, increasing platform efficiency
Notable achievements:
- Improved model inference costs while maintaining high accuracy
- Scaled to processing over 180,000 jobs daily from 12,000+ sources
- Increased monthly revenue by $5,000 through automation, job data marketting, and iterative customer based development
- Achieved 130% increase in weekly average platform usage
-
RPAL Research: Advanced Object Manipulation using Berret Hand
This research, conducted at the Robot Perception and Action Laboratory (RPAL) at the University of South Florida, focuses on enhancing robotic object manipulation through advanced machine learning techniques. Our goal is to achieve precise control in tasks such as controlled object dropping using the Berret Hand robot.
Berret Hand Representation Learning: A Multi-Objective Approach
1. Encoder: The Foundation of State Representation
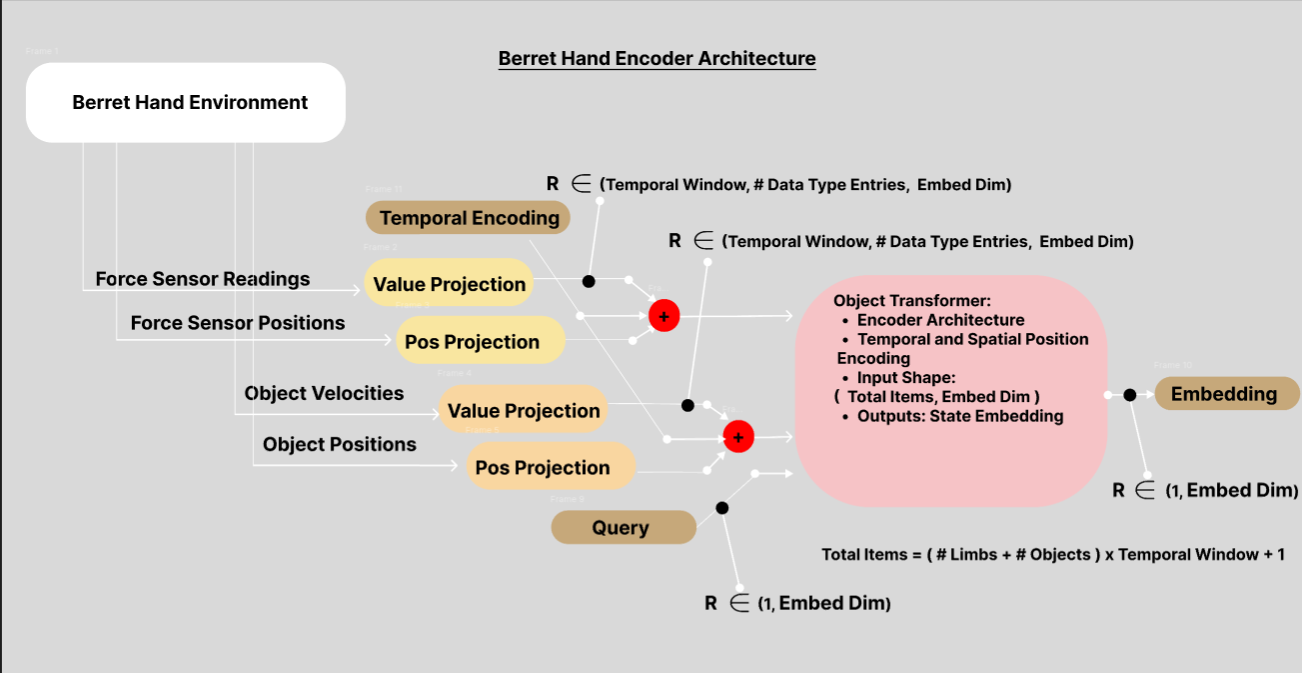
Our encoder is the cornerstone of our architecture, designed to create rich, informative state embeddings:
- Processes diverse sensor inputs: tactile data, images, torque measurements, and joint angles
- Employs a transformer-based architecture for capturing complex spatial and temporal relationships
- Trained with multiple objectives to ensure comprehensive state representation:
- Temporal encoding: Captures time-dependent features across sensor readings
- Spatial encoding: Preserves relative positions and orientations of objects and hand components
- Value encoding: Incorporates task-relevant information for decision making
- State reconstruction: Ensures the embedding retains all essential information of the original state
- Aims to create a linear learned representation, facilitating efficient state transitions and predictions
2. Dynamix Model: Forward Dynamics Prediction
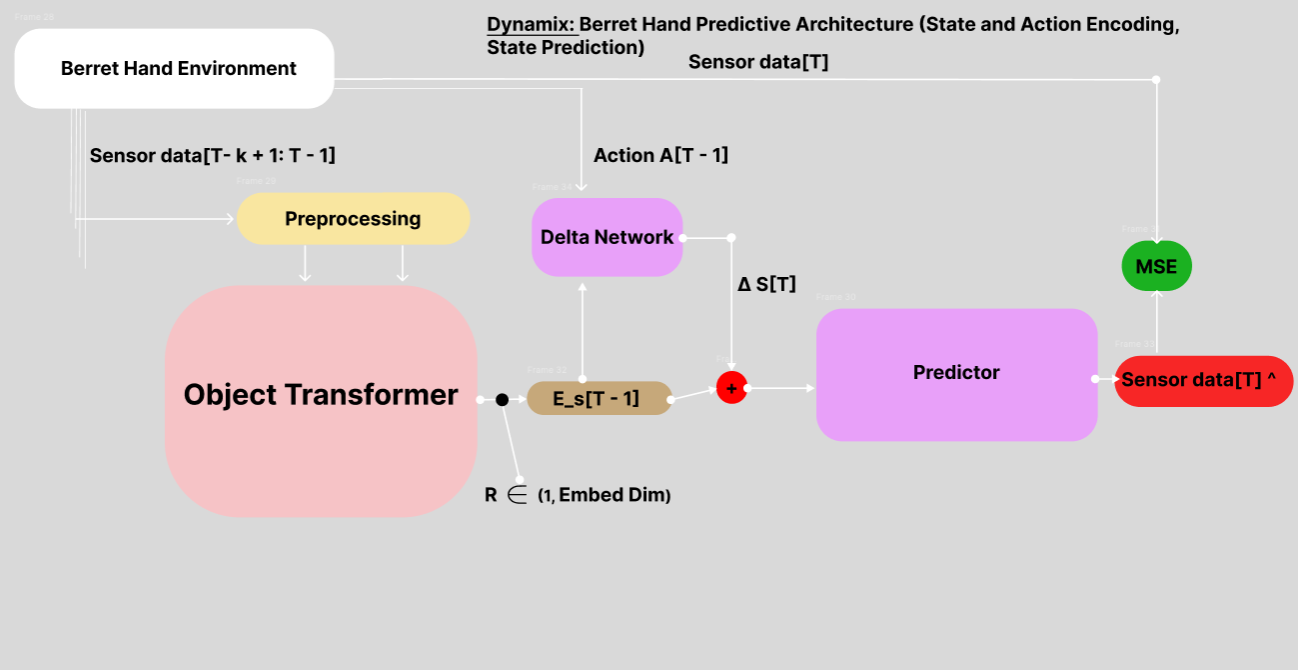
The Dynamix model leverages the encoder to predict future states:
- Inputs: Current state embedding and action
- Output: Predicted next state embedding
- Key components:
- Delta Network: Learns state transitions in the embedding space
- Predictor: Generates the next state embedding
- Enables multi-step trajectory prediction in the embedding space
3. Critiq Model: Inverse Dynamics and Reward Prediction
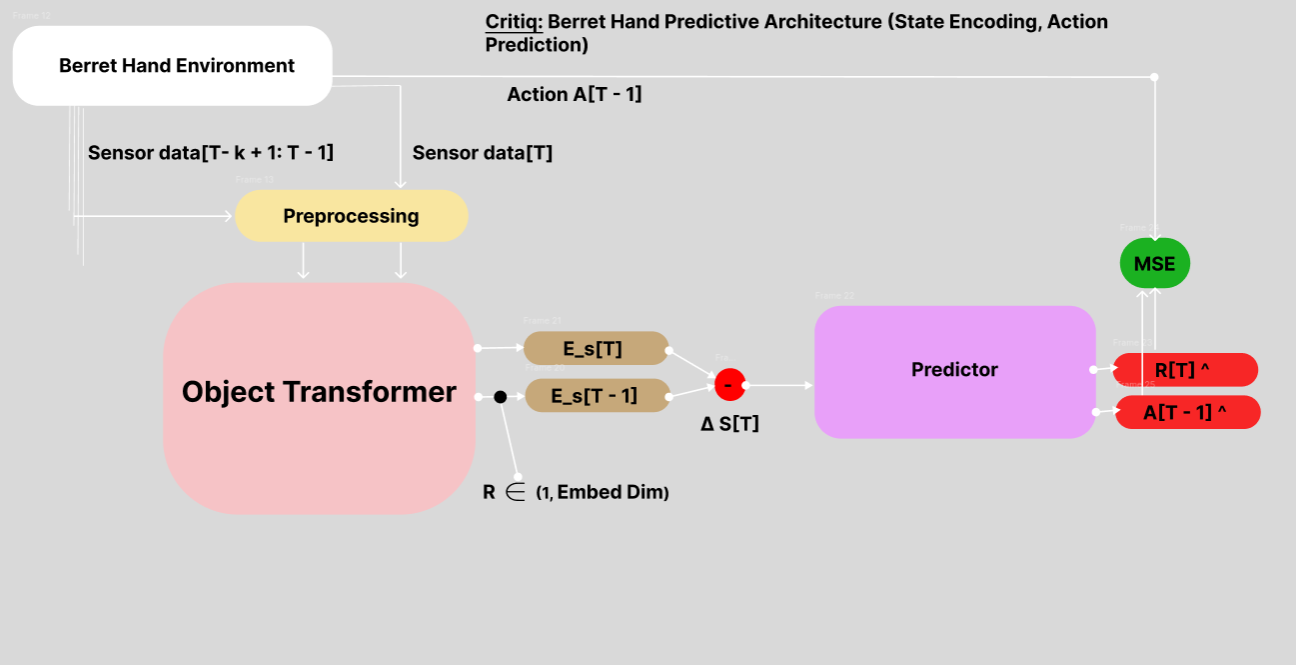
The Critiq model complements Dynamix by focusing on inverse dynamics:
- Inputs: Current and next state embeddings
- Outputs: Predicted action and reward
- Key components:
- Predictor network: Estimates actions and rewards from state transitions
- Time estimator: Provides temporal context for predictions
- Facilitates learning of action-consequence relationships and reward structures
4. Multi-Task Learning Reflection
Our approach uniquely combines forward and inverse dynamics learning:
- Shared encoder ensures consistent state representation across models
- Complementary learning objectives enhance the robustness of the state embeddings
- The architecture allows for:
- Efficient handling of complex relationships in a compact embedding space
- Flexible temporal reasoning and multi-step prediction capabilities
- Rich information extraction supporting diverse manipulation tasks
- This unified approach aims to create a versatile foundation for advanced robotic manipulation tasks
5. Results and Performance Metrics
We are currently in the process of gathering comprehensive results. Future updates will include:
- Prediction accuracy comparisons between our models and baselines
- Training and validation loss curves demonstrating learning progress
- Task completion rates for various object manipulation scenarios
- Ablation studies highlighting the impact of different architectural choices
Detailed performance graphs and metrics will be added here as results become available.
-
Teach-a-Bull (IEEE AI Group)
What if high quality education was made available to students around the world regardless of socioeconomic status; as long as they had access to the internet? Many students who have access to an internet connection are unable to afford high quality and personalized education, and because of this they may miss out on opportunities to access higher education. Likewise, many tools that exist today to combat this problem are not interactive and personalized. We present "Teach-a-Bull", an extension of the research project Large Language Models as Actors in Text-Based Environments (LLMaAiT-BE).Teach-a-Bull formalized graph-based generations over long-form text documents. For example, LLMaAiT-BE can be used formally for the generation of books, lectures, projects, papers, reports, playwrites, and more. This work enphisizes the narrow tasking and deconstruction of formal tasks into sub-components, and iteration on improval.
This work also attempted to construct vairous value metrics for assessing the quality of long-form generation documents, including the distrobution recreation hypothesis. This metric can be summarized by considering the content item which you are trying to generate, and creating a region of a vector space for which this item needs to contained in. For example, consider N documents for a lecture on 19th century Americas constructed by various experts in the field. If semantically, the generated document is contained within the span of all of these documents semantically, than we can consider this generation as a success. In other words, we are checking to see if our document has been sampled from the same distrobution as the expert-generated documents.

Research Project:
- This project extends work in LLMaAiTB-E: Graph-based generation of long-form text-based content.
- ILLMaAiTB-E: Formalizes and proposes a method to implement LLMs in complex state-based environments in which the model interacts with.
- Research project hypothesizes that LLMs can solve more complex problems by implementing a MDP
- Goal of LLMaAiTB-E: propose new methods for using LLMs to solve complex problems. Emphasis of data structure generation, argue that our method produces better generation quality via MDP modeling vs. one-shot prompting.
- Proposed a new metric in value estimating generation quality.
GitHub:
-
MicrogradPlus
An auto-differentiation computational graph library I extended from Andrej Karpathy's original Micrograd Project. This extends the original scalar differentiation to support vector-ops in a similar style to that of PyTorch. For those who are interested in auto-differentiation with n-dimensional tensors, you can fork the source code down below. All modifications made to the original source code can be validated by the testing framework embedded into the project which utilizes PyTorch's auto-differentiation.
Future Exploration:
- Introspecting optimization techniques
- Implementing a ShapeTracker; a mechanism to help determine gradients over tensors of changing sizes and dimensions.
- Incorporate kernel library for GPU support.
GitHub:
-
Numerai Competition Model (IEEE AI Group)
The IEEE AI group is tackling the Numerai Compeition with a state-of-the-art approach to data modeling. Our work attempts to combine the recent trend in large models with vast datasets to fit our models to the Numerai Competition Dataset.

Architecture:
- Numerai Feature Data ->
- N-Way Mixture Model ->
- M-Parallel Residual Blocks ->
- Fully Connected Layers ->
- 5 Feature Classifier
Currently Working On:
- Augmenting our Data for training/testing improvements.
- Test our Training Methods using a F-1 Score Threshold and Accuracy for further exploration
- Experimenting with different Training Algorithms (other than Gradient Descent)
Goal:
Develop a highly expressive model with a high enough accuracy (>90%) on our testing/competition data to enter into the Numerai Competition.
GitHub:
-
Gwen the Virtual Assistant
Welcome to the repository for Gwen, a female virtual assistant agent who is the link between your voice activated prompts and your preferred compute platform. Through Python, Gwen is provided a platform to control and manage your desktop environment in hopes to perform tasks that you might otherwise find remedial.
Current Features:
- Automated Speech responses to your questions
- Verbally engage the system using the Wakeword
- Instruct the system to play any of the configured media sources such as Spotify, Netflix, YouTube, and more!
Currently Working On:
- Add more backend capability such as having conversations over context
- Fix Keyword model, retrain on more data
- Potentially move the backend to Tinygrad
- Reduce delay from the API calls, especially with GPT-3
Future Research:
Development from here on out will take place on two different repos, 1 for Gwen and the other for the LL M server which will go onto a USF-IEEE GitHub Organization. Further enhancements include LLM Server and Trainer capabilities, Amazon integration for instant shopping, and reduction of delay in API calls. The project is open to any cool ideas, and collaboration with others brings exciting implementations into real systems. Gwen Repo | LLM Server
Amazon Integration:
- Query Item Data
- Pull Item Reviews
- Recommend Items based on reviews and scores
LLM Chains Of Thought:
-
Reinforcement Learning in Chess
This project revolves around applying reinforcement learning techniques to the game of chess, with a specific emphasis on utilizing Monte Carlo Tree Search to approximate the values of different game states through random simulations. A neural network is employed to emulate the simulation values for each node, supervised learning the state to the value discovered. As the model's approximation of value improves, reliance on state value predictions increases during the exploitation phase.
Drawing inspiration from DeepMind's AlphaGo and AlphaZero, the project aims for continuous innovation and growth. The future direction includes the integration of a policy network in addition to the value network, enhancing the complexity and effectiveness of the system.
Visit Project
-
Robbie the DanciBULL Robot - USF Hackabull Entry

In a remarkable 24-hour window, our mission was brought to life: a Simulated Robot that dances to any song. Leveraging policy and features extraction networks, the robot receives audio data and joint angles, outputting a probability distribution corresponding to the changes in each of the seventeen joints.
A unique and innovative data pipeline was constructed, using Just Dance Videos and a Joint-Angle Extraction algorithm for Offline Reinforcement Learning (RL), later perfecting the robot's motions through RL-HF. This imitation learning and pretraining process demonstrate potential for broader applications like cooking demonstrations, construction work, and painting.
The project's success exceeded expectations, turning a "huge leap of faith" into a triumphant demonstration of robot dancing. Special thanks to Matthew Elza, Kaylan Olivera, and Krish Veera for their faith, hard work, and dedication.
Visit Project -
CoderSchoolAI: Making Agent AI Simple(r)
shell> pip3 install CoderSchoolAI && python3 -c "import CoderSchoolAI"
An initiative to make theoretical CS concepts of Agent AI accessible to kids. This educational program, built on a Python Library, simplifies complex Agent AI concepts, introducing search-based and neural network-based methods for building AI agents.
A Reinforcement Learning Library which I utilize in my robotics research and many of my agent-based projects.
Guiding the creation of agents through classic and learning-based methods, CoderSchoolAI serves as a comprehensive, open-source library focused on reinforcement learning. It offers an array of tools to create, train, and test agents, including various neural network blocks, game environments, abstract classes for agents, reinforcement learning algorithms, and replay buffers.
Written in Python and integrating with PyTorch, the library's design caters to both AI newcomers and seasoned developers. The main components include:- Neural: Assorted neural network blocks and tools.
- Environment: Game environments like SnakeEnvironment.
- Agent: Base class for different reinforcement learning agents.
- Training: Reinforcement learning algorithms and training facilitators.
- Buffer: Various types of replay buffers for experience replay.
Current Features:
- RL Markov Model Environment(timestep t) -> (State, Action, New State, Reward, Done)
- Deep Q Learning with built-in Neural Block Library Support
- PPO learning with built-in Actor Critic Blocks for easy development and creation.
- Reinforcement Learning Utitities such as Replay Buffers and data tensor manipulation functions
Currently Developing:
- RL Algorithm Support for TRPO, DDPG & HER
- Generalized Monte-Carlo Tree Search (DNN/Vanilla) Based.
- Further support for different Observation and Action Spaces including Gaussian (continuous)
- Make all built-in RL Algorithms utilizable via a simplified neural network API designed for learning
GitHub: CoderSchoolAI
Whether you're an AI enthusiast, student, or researcher, this library aims to enhance your journey through AI. Feedback, suggestions, or sharing your projects are always welcome!
-
TerriBULL Robotics: BullBot - Innovations in Robotics
Collaborating within a global framework, the TerriBULL Robotics team embraced the rise of computing platforms and mainstream tech to infuse perception and automation into robotics through GPU-powered ML models and high compute devices.
Architecture & System Description: The architecture connects the V5 Brain microcontroller and Jetson for serial data communication and object detection/tracking. Key components include:- RoboController Class: Maintains overall system encapsulation.
- Task Manager: Manages autonomous actions and parallel task queues.
- Mechanical System: A higher-level abstraction layer for mechanisms like Shooters, Rollers, and Drive Systems.
- Serial Controller: Manages data transmission, linked with Jetson Controller.
- Jetson: Offloads computations for vision and calibration.
- Decision Model: Improves accuracy in path planning and object manipulation.
New Research Focus: The Programming and AI Team is devoted to top-level competition through Software System Development and Machine Learning. It strives for optimized robot control and data throughput, while leveraging cutting-edge research in machine learning and Reinforcement Learning. The goal encompasses robust models for complex tasks, nonconventional model-based techniques, and data compression algorithms to enhance data transfer bandwidth. Our current focus is in robot modeling within a simulated environment, using offline and online reinforcement learning algorithms (DDPG+HER). Our goal is to have the robot learn the optimal policy for competing in the VEX Competition.
GitHub: BullBot | Competition Video
-
Astaria: 2D Action RPG Adventure
Astaria is a captivating 2D Action RPG game, akin to the Pokemon series, built using the Godot engine. This solo project spans over a month and offers an enthralling gaming experience.
Game Features:- Arcade Mode: Players face waves of relentless Bat enemies, each capable of damaging the player. Strategize and defeat them!
- Health Potions & Weapon Upgrades: Keep an eye out for bat droppings that occasionally reward potions for health recovery and exciting weapon system upgrades.
- Charming Visuals: Experience the world of Astaria with delightful 2D graphics and engaging gameplay dynamics.
GitHub: Astaria Project